Machine learning yield models are only as good as their calibration data. This is a point the remote sensing community has debated extensively in academic literature, but it rarely gets stated plainly to the insurance and trading professionals who are evaluating satellite yield products commercially. Our corn and soybean yield models are calibrated against USDA NASS county-level yield surveys as held-out ground truth, and this article explains exactly what that process looks like, where it works well, and where it produces systematic uncertainty that users need to account for.
Why USDA NASS County Surveys Are the Right Ground Truth
There are several sources of yield ground truth a satellite data provider might use for calibration: farmer-reported APH yields from RMA records (detailed but access-restricted and geographically partial), harvest monitor data from precision agriculture platforms (high resolution but not representative), or USDA NASS county yield surveys.
We use NASS county yields as the primary calibration target for two reasons. First, they are publicly available, annually consistent, and cover all major corn and soybean counties in CONUS going back to the 1970s — a depth of historical record that provides enough data to capture drought years, La Niña years, and high-yield years as distinct distributional outcomes rather than one blended average. Second, they represent the same geographic unit — the county — that insurance actuaries use as their pricing reference. A yield model calibrated against county-average NASS data is directly comparable to the county actuarial factors that underwriters work with, making relative performance claims interpretable.
The limitation — and we're explicit about it in our methodology documentation — is that NASS county yields are themselves survey-based estimates with associated uncertainty. NASS publishes standard errors for state-level estimates, and county-level estimates carry higher relative error (typically ±3-6% for major corn counties, higher for smaller-acreage counties). Calibrating against a noisy ground-truth label introduces a floor on achievable model accuracy that is independent of model architecture.
The Calibration Dataset: Construction and Held-Out Validation
Our calibration dataset for corn spans model years 2016-2024 across 312 USDA NASS corn reporting counties, primarily in the I-states (Iowa, Illinois, Indiana), Nebraska, Minnesota, and Ohio — the counties that together account for roughly 65% of US corn production and have sufficient reporting density for reliable NASS county estimates. For soybeans, we use 289 counties with similar geographic coverage.
The feature set for each county-year observation includes:
- Cumulative NDVI anomaly from emergence through reproductive development (the ratio of in-season NDVI to historical mean NDVI, integrated from V4 to R5 in corn)
- Growing degree day accumulation and deviation from 1990-2020 climatological normal, from planting through silking
- Palmer Drought Severity Index for the county, averaged across the August period
- Vegetation condition ratio at peak greenness (NDVI at peak versus 10-year peak mean)
- SWIR-derived moisture stress index from Sentinel-2 Band 11/12 during the reproductive window
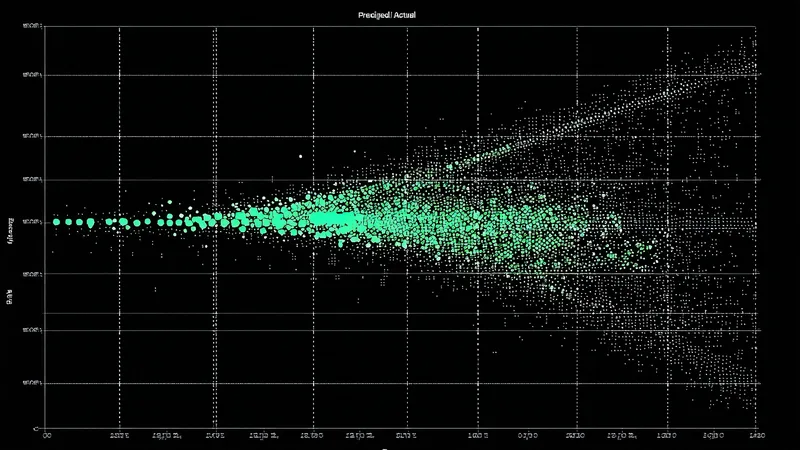
We use leave-one-year-out cross-validation (LOYO-CV) as the primary validation protocol rather than a simple train/test split. LOYO-CV is the appropriate methodology here because crop yields exhibit strong year effects — correlated outcomes across counties within a season driven by large-scale weather patterns — that would produce overly optimistic accuracy metrics in a random train/test split that mixes years. In LOYO-CV, the model is retrained 9 times (once per year from 2016-2024), each time holding out a complete growing season year, and evaluated on counties in the held-out year.
What the Validation Metrics Actually Show
Across the 2016-2024 LOYO-CV validation period, our corn yield model produces the following performance metrics against NASS county ground truth:
- County-level RMSE: 11.4 bu/acre (range 8.2-15.7 bu/acre depending on year)
- Mean absolute percentage error (MAPE): 6.1%
- R² (county yield deviation explained by model): 0.74
- Worst year (2019, abnormal planting delays): RMSE 15.7 bu/acre, MAPE 8.3%
- Best year (2022, clear-sky July, normal season): RMSE 8.2 bu/acre, MAPE 4.7%
For soybeans, county-level RMSE is 4.2 bu/acre (MAPE 7.8%), reflecting the relatively lower within-year variance of soybean yields compared to corn. The R² for soybeans (0.69) is slightly lower than corn, consistent with the agronomic expectation that soybeans show more compensatory ability during mid-season stress events, making early-season NDVI signals a somewhat weaker predictor of final soybean yield.
The 2019 performance deserves specific comment. 2019 was a historically abnormal year in which widespread prevented planting events across the upper Midwest resulted in late-planted corn and soybeans on fields that were ultimately planted, with many fields replanted to soybeans after corn planting dates passed. Optical NDVI timing signals — which the model uses to infer crop development stage — were significantly disrupted by the late, variable planting dates. The elevated RMSE in 2019 is not a model failure in the classical sense; it reflects a year where the training data relationship between NDVI trajectory and yield outcome was genuinely disrupted by an agronomic anomaly that satellite imagery alone could not fully capture.
Field-Level Accuracy vs. County-Level Accuracy
The LOYO-CV metrics above are county-level validation results. Field-level accuracy — which is what matters for APN-level insurance applications — is meaningfully different and harder to validate at scale.
Field-level validation requires field-level ground truth, which USDA NASS does not provide. We use two supplementary validation approaches for field-scale accuracy assessment: (1) comparison against a small set of farm operation yield data from cooperating growers who share their combine yield monitor data under data-sharing agreements, and (2) within-county distribution analysis that compares the spread of field-level yield predictions within a county against the empirical within-county yield distribution estimated from RMA APH records where available.
These validation approaches are less rigorous than the LOYO-CV county validation, and we treat field-level accuracy claims accordingly. The county-level RMSE of 11.4 bu/acre for corn is a defensible, publicly replicable validation result. Field-level accuracy for a specific 80-acre parcel carries wider uncertainty — our internal estimates suggest field-level RMSE approximately 1.4-1.8x the county-level RMSE, reflecting spatial heterogeneity within county units that the county-average calibration target cannot fully capture.
What This Means for Users Who Depend on the Model
The relevant implication for an insurance actuary or commodity trader using satellite yield estimates is not the headline RMSE — it's the uncertainty bounds propagated through to the P10/P50/P90 distribution delivered in the API response. The yield model does not output a single point estimate. It outputs a probability distribution that reflects both the model's central estimate and the empirically calibrated uncertainty from the LOYO-CV validation history.
When the API returns a P50 of 172 bu/acre with a P10 of 156 bu/acre for a specific county in mid-August, the P10/P50 spread reflects the actual distribution of county-level outcomes we observed in LOYO-CV validation years with similar mid-season NDVI trajectories. A P10 that is 16 bu/acre below P50 represents a real historical downside range — not an arbitrary confidence interval selected for aesthetic reasons. That transparency about model calibration and validation methodology is what makes yield probability distributions operationally useful rather than merely decorative.